
Big Endian and Little Endian
A load word or store word instruction uses only one memory address. The lowest address of the four bytes is used for the address of a block of four contiguous bytes.
How is a 32-bit pattern held in the four bytes of memory? There are 32 bits in the four bytes and 32 bits in the pattern, but a choice has to be made about which byte of memory gets what part of the pattern. There are two ways that computers commonly do this:
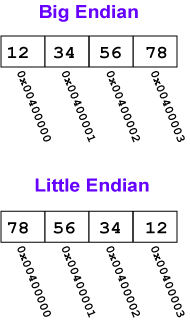
Big Endian Byte Order: The most significant byte (the “big end”) of the data is placed at the byte with the lowest address. The rest of the data is placed in order in the next three bytes in memory.
Little Endian Byte Order: The least significant byte (the “little end”) of the data is placed at the byte with the lowest address. The rest of the data is placed in order in the next three bytes in memory.
In these definitions, the data, a 32-bit pattern, is regarded as a 32-bit unsigned integer. The “most significant” byte is the one for the largest powers of two: 231, …, 224. The “least significant” byte is the one for the smallest powers of two: 27, …, 20.
For example, say that the 32-bit pattern 0x12345678 is stored at address 0x00400000. The most significant byte is 0x12; the least significant is 0x78.
Within a byte the order of the bits is the same for all computers (no matter how the bytes themselves are arranged).
一、字节序
字节序,也就是字节的顺序,指的是多字节的数据在内存中的存放顺序。
在几乎所有的机器上,多字节对象都被存储为连续的字节序列。例如:如果C/C++中的一个int型变量 a 的起始地址是&a = 0x100,那么 a 的四个字节将被存储在存储器的0x100, 0x101, 0x102, 0x103位置。
根据整数 a 在连续的 4 byte 内存中的存储顺序,字节序被分为大端序(Big Endian) 与 小端序(Little Endian)两类。 然后就牵涉出两大CPU派系:
- Motorola 6800,PowerPC 970,SPARC(除V9外)等处理器采用 Big Endian方式存储数据;
- x86系列,VAX,PDP-11等处理器采用Little Endian方式存储数据。
另外,还有一些处理器像ARM, DEC Alpha的字节序是可配置的。
二、大端与小端
那么,到底什么是大端,什么是小端? 如下图:

我相信上面的图已经够直观了。也就是说:
- Big Endian 是指低地址端 存放 高位字节。
- Little Endian 是指低地址端 存放 低位字节。
各自的优势:
- Big Endian:符号位的判定固定为第一个字节,容易判断正负。
- Little Endian:长度为1,2,4字节的数,排列方式都是一样的,数据类型转换非常方便。
三、为什么要注意字节序
如果你写的程序只在单机环境下面运行,并且不和别人的程序打交道,那么你完全可以忽略字节序的存在。
但是,如果你的程序要跟别人的程序产生交互呢? 比如,当一个 C/C++ 的程序要与一个 Java 程序交互时:
- C/C++语言编写的程序里数据存储顺序是跟编译平台所在的CPU相关的,而现在比较普遍的 x86 处理器是 Little Endian
- JAVA编写的程序则唯一采用 Big Endian 方式来存储数据
试想,如果你的C/C++程序将变量 a = 0x12345678 的首地址传递给了Java程序,由于Java采取 Big Endian 方式存储数据,很自然的它会将你的数据翻译为 0x78563412。显然,问题就出现了!!!
另外,网络传输一般采用 Big Endian,也被称之为网络字节序,或网络序。当两台采用不同字节序的主机通信时,在发送数据之前都必须经过字节序的转换成为网络字节序后再进行传输。
四、判断机器的字节序
由于 C/C++ 存储数据时的字节序依赖所在平台的CPU,所以我们可以通过C/C++程序判定机器的端序:
1 | void Endianness() |
五、网络序和主机序
网络字节序:TCP/IP各层协议将字节序定义为 Big Endian,因此TCP/IP协议中使用的字节序是大端序。
主机字节序:整数在内存中存储的顺序,现在 Little Endian 比较普遍。(不同的 CPU 有不同的字节序)
在进行网络通信时 通常需要调用相应的函数进行主机序和网络序的转换。Berkeley socket API 定义了一组转换函数,用于16和32bit整数在网络序和本机字节序之间的转换。htonl,htons用于本机序转换到网络序;ntohl,ntohs用于网络序转换到本机序。